SPSS로 배우는 통계 - 1. 변수 다루기
SPSS는 통계 분석과 데이터 마이닝에 사용하는 통계 분석 프로그램으로 전 세계에서 가장 많이 사용합니다. SPSS는 Statistical Package for the Social Sciences의 약어로 사회 과학을 위한 통계 패키지라는 의미로 IBM이 배포합니다. 양적 연구를 위한 논문을 작성할 때 SPSS 통계 프로그램을 주로 사용합니다. 경영학 및 사회과학 등의 분야에서 설문 조사 및 통계 분석에 SPSS는 강력한 성능을 발휘합니다. SPSS는 통계학 강의의 필수 애플리케이션입니다. .
SPSS는 3 가지 제품이 있습니다. 가장 널리 사용되는 SPSS Statistics는 데이터 분석을 위한 계획, 데이터 수집 및 분석 그리고 보고서를 만드는 모든 과정을 지원합니다. SPSS Modeler는 가설을 세우고 예측 모델링을 위한 알고리즘을 구현하는 전문 데이터 마이닝 툴로 데이터 사이언티스트와 애널리스트들이 많이 사용합니다. SPSS Amos는 손쉬운 구조 방정식 모델링 기법을 사용하여 복잡한 변수 관계에 대한 가설을 테스트합니다.
SPSS는 가격이 상당히 높고, 14일 체험판이 있습니다. SPSS Statistics는 윈도즈와 맥 운영체제를 모두 지원합니다. 필자도 대학원에서 SPSS 사용법과 통계를 배우면서 내용을 정리합니다.
변수의 개요
변수의 정의
변수(Variable)는 하나 이상의 값을 가지는 실체입니다. 변수와 반대되는 의미로 상수가 있고, 항상 일정한 값을 가지는 실체입니다. 다음과 같은 방정식이 있을 때,
y = 2x + 1
여기서, x와 y는 변수입니다. 2와 10은 상수입니다. 상수는 변하지 않는 값입니다. x는 1,2,3,4,5,6 등의 값이 될 수 있고, y도 x의 값에 따라 3,5,7,9,11,13 등의 값이 될 수 있습니다. 단순하게 변수는 변화하는 값이고, 상수는 고정된 값입니다.
따라서, 양적 연구에서 가설은 변수들의 상관관계를 규명하는 것입니다. 변수는 여러 가지 종류가 있습니다.
독립 변수와 종속 변수
독립 변수(Independent Variable)는 다른 변수에 영향을 받지 않고 독립적으로 존재하고, 종속 변수(Dependent Variable)는 독립 변수에 영향을 받습니다. 다음과 같은 방정식이 있을 때
y = 2x + 10
여기서, 변수는 x와 y입니다. x는 독립변수이고 y는 종속변수입니다. 방정식에서 독립변수 x의 값에 따라 종속변수 y의 값이 결정됩니다. x에 1,2,3,4,5,6 등의 값을 선택할 때마다 자동으로 y의 값이 결정됩니다.
따라서, 양적 연구에서 독립 변수의 변화를 추적하여 종속 변수의 변화를 관찰합니다. 인과 관계로 볼 때 독립변수는 원인을 의미하고, 종속변수는 결과를 의미합니다. 원인을 의미하는 독립변수를 다른 말로 설명 변수 (Explanatory Variable), 예측 변수 (Predictor Variable), 위험요소 (Risk Facto)라고 하고, 결과를 의미하는 종속 변수를 다른 말로 반응 변수 (Response Variable), 결과 변수 (Outcome variable), 표적 변수 (Target Variable)이라고 합니다.
예를 들어, 수업 방법에 따른 학업 성취도를 측정할 때 수업 방법은 강의식과 토의식이 있고, 학업 성취도는 성적입니다. 원인이자 독립변수는 수업방법이고, 결과이자 종속 변수는 학업 성취도입니다. 연구자는 수업 방법을 결정할 수 있지만, 종속 변수는 제어할 수 없습니다.
또 다른 예로 서울의 지역구별 소득 차이를 조사할 때 원인이자 독립 변수는 지역구이고, 결과이자 종속 변수는 소득입니다. 연구자는 지역구를 선택할 수 있지만, 소득은 제어할 수 없습니다.
매개 변수와 조절 변수
매개변수 (Mediator Variable)는 두 변수의 관계를 맺어주는 변수입니다. 매개 변수는 독립 변수와 마찬가지로 종속 변수에 영향을 미치지만 순서적으로 독립변수와 종속변수 사이에 있습니다. 독립 변수의 영향을 받으면서 종속 변수에 영향을 미치는 변수입니다. 다음과 같은 방정식이 있을 때
y = ax + 10
여기서, 변수는 a, x와 y입니다. x는 독립변수이고 y는 종속변수이고, a는 매개변수입니다. a는 독립변수 x가 종속변수 y에 영향을 미치는 영향의 정도를 나타냅니다.
예를 들면, 연령에 따른 직무 만족도를 평가할 때 연령은 독립 변수이고 직무 만족도는 종속 변수입니다. 여기서 연봉에 따른 종속 변수 직무 만족도의 차이가 있고, 연령과 연봉 사이에도 미치는 영향이 있습니다. 연령이 높을수록 연봉이 상대적으로 낮아도 직무 만족도가 높고, 연령이 낮을수록 연봉이 상대적으로 높아야 직무 만족도가 높습니다.
조절 변수 (Moderator Variable)은 종속 변수에 영향을 주는 제3의 변수로 독립 변수에 영향을 받지 않고 종속 변수에 영향을 미치는 변수입니다. 다음과 같은 방정식이 있을 때
y = ax' + 10 + bx''
여기서, 변수는 a, x', x''와 y입니다. x'와 x''는 독립변수이고 y는 종속변수이고, a는 매개변수입니다. x'는 주 독립변수이고, x''는 조절변수로 종속변수 y에 영향을 미칩니다.
예를 들면, 수업 방법에 따른 학업 성취도를 측정할 때, 수업 방법은 강의식과 토의식이 있고, 학업 성취도는 성적입니다. 원인이자 독립변수는 수업방법이고, 결과이자 종속 변수는 학업 성취도입니다. 여기서 성별에 따라 학업 성취도가 달라진다고 가정할 때, 주요 독립 변수는 수업 방식이고, 독립 변수와 무관한 제 2의 독립 변수 성별이 종속 변수인 학업 성취도에 영향을 미치는 것입니다.
능동 변수와 속성 변수
능동 변수 (Active Variale)는 조작할 수 있고, 속성 변수(Attribute Variable)는 조작할 수 없습니다. 조작(Operation)은 연구의 목적에 따라 실험 대상에 서로 다른 방법을 적용한다는 것입니다.
예를 들면, 수업 방법에 따른 학업 성취도를 측정할 때, 한쪽 그룹은 강의식으로 수업하고, 다른 그룹은 토의식으로 수업을 합니다. 연구자가 수업 방법을 능동적으로 조작한 것으로 교수 방법은 능동 변수입니다. 연구자는 두 그룹의 성별, 지능, 교육 수준을 인위적으로 조작하지 않고 동일하게 유지합니다. 성별, 지능, 교육 수준은 속성 변수입니다.
연속 변수와 불연속 변수
척도에 따라 연속 변수(Continous Variable)와 불연속 변수 (Discrete Variable)로 나뉩니다. 연속 변수는 온도, 길이, 가격 등과 같이 연속된 값을 가집니다. 가격이나 길이를 반올림 또는 반내림을 하면서 불연속이라고 생각할 수 있지만, 연속이라고 정의합니다. 불연속 변수는 디지털의 0과 1처럼 연결되지 않은 척도입니다
대표적인 연속 변수의 척도는 등간 척도(interval scale)와 비율 척도(ratio scale)입니다. 등간 척도는 변수의 양적 차이를 균등하게 분할하여 측정하고 절대 0점이 없습니다. 대표적인 등간척도는 온도이고, 0도는 어는점일 뿐 온도가 없다는 의미가 아닙니다. 비율 척도는 서열, 등간 비율의 모든 것을 가지고 절대 0점이 있습니다. 대표적인 비율 척도는 거리, 무게, 시간이고 거리와 시간이 없는 0이 있습니다.
. 대표적인 불연속 척도는 명목 척도와 순위 척도입니다. 명목 척도 (Nominal Scale)는 이름으로 구분하는 것으로 성별, 국적, 직업, 지역, 학력 등입니다. 명목 척도는 숫자로 표현되기도 하지만 수량의 의미가 아닌 카테고리의 의미가 더 강합니다. 순위 척도는 이름 그대로 순위를 나타내는 척도입니다.
외생 변수와 통제 변수
외생변수(exogenous variable)는 독립변수 외에 종속 변수에 영향을 주는 모든 변수를 의미하고, 통제 변수는 수많은 외생 변수 중에서 적절하게 통제한 변수입니다.
예를 들면, 불안의 정도에 따른 공격성의 정도를 측정할 때, 독립변수는 불안의 정도이고, 종속변수는 공격성의 정도입니다. 외생 변수는 충동성, 민감성, 성별은 종속변수에 영향을 주는 외생 변수들이고, 실험에서 적절하게 통제가 된 변수는 통제 변수이다.
SPSS로 변수 코딩하기
설문 조사 결과를 SPSS로 이해할 수 있는 데이터로 변경합니다.
기본 코딩
케이블 TV 쇼핑 구매 경험 소비자 대상 설문지를 SPSS로 코딩을 합니다. 질문의 유형별로 SPSS로 코딩하는 법을 정리합니다.
단일 선택 질문 (Yes Or No)
질문) 귀하는 케이블 TV 쇼핑에서 금년에 제품을 구매한 적이 있습니까?
(1) 구매한 적이 없다 (2) 구매한 적이 있다
변수명은 구매경험으로 지정하고, 답변을 0과 1로 나타냅니다. 구매한 적이 없다는 0으로 구매한 적이 있다는 1로 표시합니다.
다중 선택 질문
질문) 귀하가 금년에 케이블 TV 쇼핑에서 구매한 제품은 다음 중 어느것입니까? 모두 표기해 주세요.
(1) 식품 (2) 의류 (3) 운동기구 (4) 가전 제품 (5)기타
하나의 변수로 선언할 수 없습니다. 각 답변 항목별로 변수를 지정하고 구매한 적이 없다는 0으로 구매한 적이 있다는 1로 표기합니다. 변수는 식품구매, 의류구매, 운동기구구매, 가전제품 구매, 기타구매로 변수룰 지정하고 각 응답에 따라 0과 1을 값으로 지정합니다.
만족도 질문
귀하가 케이블 TV 쇼핑에서 구매한 후의 전체적인 만족도는 어느 정도입니까?
(1) 매우 불만족 (2)불만족 (3) 보통 (4) 만족 (5)매우 만족
변수명은 만족도로 지정하고, 각 답변을 1에서 5로 지정합니다. 매우 불만족은 1, 불만족은 2, 보통은 3, 만족은 4, 매우 만족은 5로 표시합니다.
위의 질문들을 다음과 같이 SPSS에 코딩합니다.

변수를 지정하기
액셀과 똑같은 모양의 창이 데이터를 표시하는 기본 창입니다. 왼쪽 화면은 데이터 창이고, 오른쪽은 변수 창입니다.


SPSS는 변수 창에서 변수의 속성을 변경하거나 지정할 수 있습니다.
변수 이름 변경 : 5개의 변수에 대한 이름(Name)을 변경
소수점 이하의 자릿수 지정 : 기본 2자리로 된 것을 0으로 변경하여 자연수로 표현
레이블 : 변수 이름으로 이해하기 어려울 경우 레이블에 상세 표기
값 : 변수에서 사용할 값을 지정
성별 변수는 1은 남자, 2는 여자
만족도 변수 1은 전혀 만족스럽지 않다, 2는 만족스럽지 않다, 3은 보통이다, 4는 만족스럽다 등

리코드 (Recode)
설문 조사를 할 때 역척도를 사용하기도 합니다. 설문자들이 질문의 내용을 제대로 읽지 않고 무조건 왼쪽의 번호를 선택하거나 오른쪽의 번호만 선택하는 경우가 있습니다. 역척도는 성의가 없는 답변을 걸러내는 방법 중 하나입니다. 설문은 역척도로 설계하더라도 통계를 위한 SPSS 프로그램에서는 동일하게 척도를 사용해야 합니다. 리코드(Recode)는 역척도를 바로 잡아 주는 역할을 합니다.
우선 데이터를 숫자로 보거나 값의 레이블로 보거나 선택할 수 있습니다. 통계에서 볼 때는 숫자로 보는 것이 편합니다. 메뉴바에서 숫자와 알파벳으로 된 아이콘 Value Labels을 클릭하면 데이터가 숫자 또는 레이블로 전환합니다.
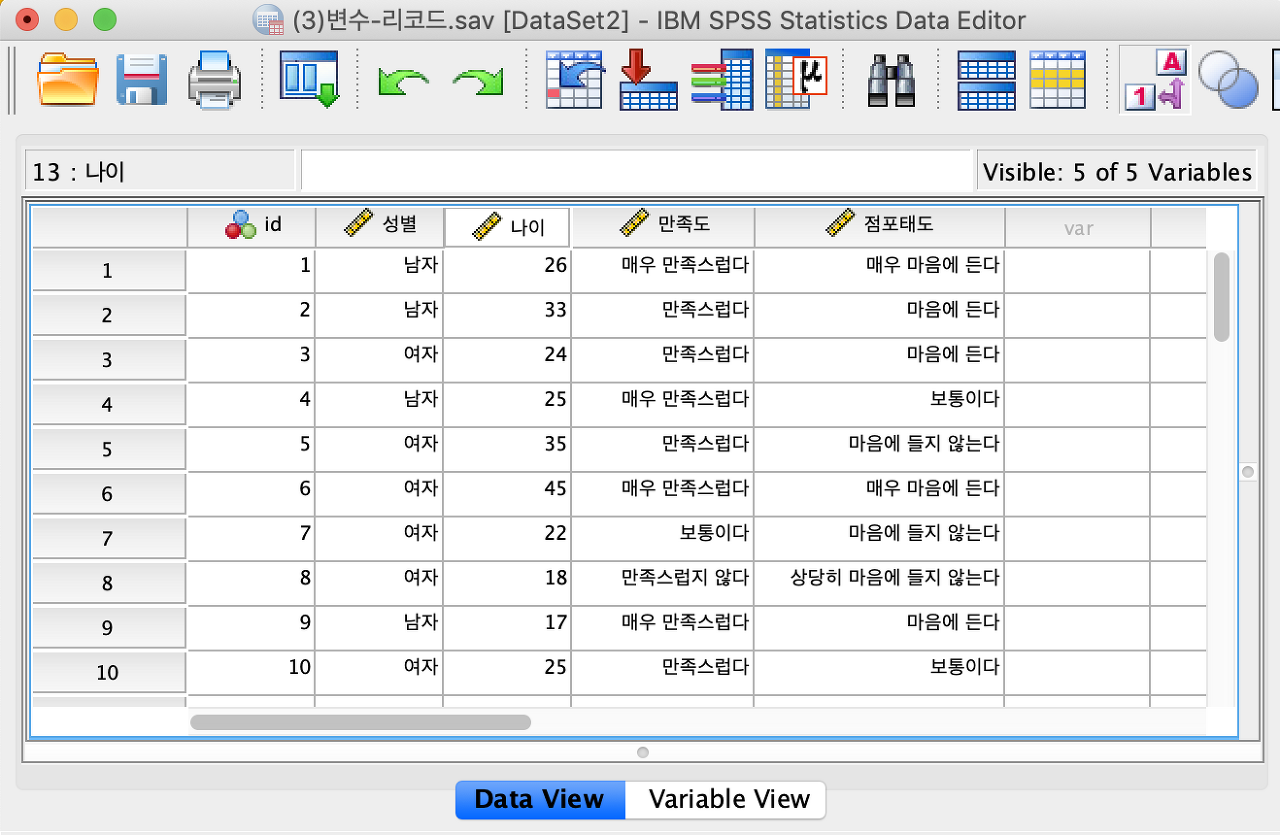

리코드는 두 가지 방법이 있습니다. 같은 변수로 코딩을 변경하는 것과 다른 변수로 코딩을 변경하는 것입니다. 여기서는 같은 변수로 코딩을 변경합니다.
1) 메뉴바에서 "변환 >> 같은 변수로 코딩 변경"을 선택합니다.

2) 같은 변수로 코딩 변경 창에서 리코드를 할 변수를 선택하고 "기존값 및 새로운 값" 버튼을 클릭합니다. 그리고, 기존값과 새로운 값에 숫자를 넣고 추가 버튼을 누릅니다. 역척도를 변경하는 것이므로 1과 7을 바꾸어줍니다.

변수 합치기 (Compute Value)
두 개 변수가 같은 의미를 가지므로 새로운 변수로 만드는 것이 효과적일 때가 있습니다. 설문 조사에서 뉘앙스를 달리하여 비슷한 질문을 합니다. 이 값 중에 어느 것을 사용하기 힘들기 때문에 평균값을 사용합니다. 예제에서 점포 만족도와 점포 태도는 매우 유사하므로 점포 평가라는 새로운 변수를 만들어서 두 값에 평균을 취합니다.
1) 메뉴바에서 "변환 >> 변수 계산"을 선택합니다.

2) 새로운 변수명을 입력하고 두 변수를 합한 값을 2로 나누는 식을 넣습니다.

3) 점포 평가 변수가 생성되었습니다.

일부 데이터만 사용하기 (Compute Value)
방대한 데이터의 일부 케이스만을 이용하여 분석할 수 있습니다. 예를 들면, 성별이나 나이에 따라 특정 데이터를 선택합니다.
1) 메뉴바에서 "데이터 >> 케이스 선택"을 선택합니다.

2) "케이스 선택" 창에서 성별을 선택하고 "조건을 만족하는 케이스" 버튼을 클릭하고 "조건"을 선택합니다. 그리고 성별의 값이 1 또는 2를 선택합니다. 1은 남자 2는 여자입니다.

3) 새롭게 Filter 변수가 생기면서 성별의 값이 1이 아닌 경우를 제외합니다.

테스트 데이터