AI 자산운용 보고서
인공지능은 어떤 방식으로 자산운용을 혁신할 수 있을까
English version: https://medium.com/qraft/ai-asset-management-report-e04eab80d664
자산운용의 혁신은 외부로 잘 드러나지 않는다.
자산운용의 수요자인 투자자(고객)는 자산운용사의 브랜드와 수익률에는 관심이 높지만, 실제 자산이 운용되는 방식에 대해서는 상대적으로 무관심하다. 그리고 자산운용은 상대평가/제로썸의 성격을 지니기 때문에 자산운용업자는 힘겹게 이룬 혁신을 혼자 오래 독점하려고 한다. 그래서, 자산운용의 혁신은 외부로 잘 드러나지 않는다.
그러나, 자산운용분야에서는 조용히 많은 혁신이 이루어져왔고 지금도 현재진행형이다. 인공지능 기술에 의한 자산운용의 혁신가능성을 알아보기에 앞서, 앞서 어떤 혁신들이 있었는지를 먼저 살펴보면 인공지능 기술이 이를 이을만한 후보인지에 대한 힌트를 얻을 수도 있을 것이다.
매일 어제 반대로 투자하기: 전략 C
다음과 같은 간단한 주식투자전략이 있다. (편의상 '전략C'라고 하자. Contrarian strategy의 약자이다)
매일 아침 장 시작전에 데이터를 통해 매일 가장 많이 오른 종목과 가장 많이 떨어진 종목을 찾는다.
시가에 전일 하락률이 높은 종목을 산다. (종목당 매수금액은 하락률의 크기대로 배분한다. 즉, 많이 하락한 종목을 더 많이 산다.)
시가에 전일 상승률이 높은 종목을 공매도한다. (종목당 공매도금액은 상승률의 크기대로 배분한다. 즉 더 많이 오른 종목을 더 많이 공매도한다.)
시장 오르내림에 영향을 받지 않기 위해, 매수금액과 공매도 금액을 같게 맞춘다. (market neutral portfolio)
이를 매일 반복한다.
단순한 전략이다. 그러나, 그 결과는 엄청나다.
 * Amir E. Khandani and Andrew W. Lo, 2007, "What Happened To The Quants In August 2007?"
* Amir E. Khandani and Andrew W. Lo, 2007, "What Happened To The Quants In August 2007?"위의 표를 해석하면, 이 단순한 데일리 콘트래리안 전략은 1995년도에 매일 평균 1.38%의 수익률을 기록했다. (소형주 그룹에서만 이 전략을 실행했다면 일평균 3.57% 수익률) 연환산 30배의 수익이다. 샤프비율은 무려 53.87에 달해서 사실상 리스크가 거의 없는 수준이다.
전략C는 1990년에 최초로 논문으로 발표되었고, 헤지펀드들에 의해 사용되기 시작한 것은 그보다 좀더 이전으로 알려져있다. D.E. Shaw&Co., 르네상스테크놀로지스 등 현재 잘나가고 있는 대형 퀀트펀드들 역시 전략C를 사용하여 엄청난 돈을 벌었고, 이를 밑천으로 초기에 회사규모를 크게 키울 수 있었다. 유명 퀀트펀드 PDT Partners 역시 전략C로 떼돈을 벌었던 모건스탠리 자기자본거래그룹이 전신이다.
위의 표에서도 알 수 있듯이 많은 펀드들이 앞다투어 이 전략을 사용하게 되자 1995년 하루 1.38%에 달하던 전략C의 수익률은 2007년에는 0.13%까지 줄어들었고, 일간변동성은 2배 가까이 확대되었다. 그러나, 여전히 많은 퀀트펀드들은 해당 전략을 고도화시킨 버전(포트폴리오를 인더스트리별로 뉴트럴라이즈 하여 위험성을 낮추거나, 좀더 전략이 잘 동작하는 상황을 찾아보는 등)을 활발하게 사용하고 있다.
2007년 발표된 논문 "What Happened To The Quants In August 2007"는 퀀트펀드들이 전략C에서 파생된 데일리 콘트래리안 전략들을 사용하고 있으며, 2007년에 퀀트펀드 몇 곳이 보유 포지션을 덤핑하자 전략C의 수익률이 급락하여 시장은 큰 변화가 없었음에도 퀀트펀드들의 수익률이 동시에 급락하였음을 보여주었다.(해당 논문의 공저자인 Andrew Lo는 1990년에 전략C에 대한 논문을 최초로 발표한 MIT 교수로, 홍콩에서 태어나 하버드, 예일대에서 수학한 중국계 금융학자이다.) 르네상스테크놀로지스의 제임스 사이먼스도 당시 르네상스 기관펀드의 성과가 급락하자 "비슷한 전략을 사용하는 다른 펀드의 포지션이 시장에서 빠르게 청산되었고 그 영향으로 펀드 수익률이 급감하였다"라고 급하게 변명한 흑역사가 있다.
여기서 두가지 의문이 떠오른다.
왜 저런 단순하고 강력한 전략을 1990년에 되서야 발견할 수 있었을까?
왜 해당전략이 발표된 1990년 이후에도 오랫동안 전략이 잘 동작했을까?
사실 두 질문에 대한 답은 같으며, 그 답은 인공지능 기술을 통한 자산운용 혁신과도 깊게 연결되어 있다.
종목에서 포트폴리오로 : Statistical Arbitrage 의 시작
매일 많이 오른 종목을 공매도하고 많이 떨어진 종목을 매수하는 것을 반복하며, 매수금액과 공매도 금액을 같게 유지하여 시장(베타)의 영향을 제거하는 전략C는 매우 단순하지만 수익률은 엄청났다. 수많은 사람들이 돈을 벌기위해 그토록 열심히 투자를 연구했지만, 1980년대 후반이 되서야 소수의 사람들만이 이를 겨우 알아채고 큰 돈을 벌기 시작했다. 그 이유는 무엇일까?
사실, 전략C에 도달하기 위해서는 모든 주식에 대한 과거 일간 가격데이터와 간단한 프로그래밍이 가능한 컴퓨터만 있으면 된다. 이 조건은 1950년대에도 충족된다. 그러나, 필요조건은 충분조건과 다르고 도달가능한 것과 실제 도달하는 것은 큰 차이가 있다. 1980년대에 과거 주식 가격 데이터를 전부 구할 수 있고, 컴퓨터도 가지고 있는 사람이 전략C를 프로그램하여 테스트할 수 있는 사람과 동일인일 확률은 0에 가까웠다.
1980년대로 돌아가본다면 피터린치 등의 스타매니저와 적대적 M&A 레이더스('프리티우먼'의 배경)들이 전성기를 누리고 있었고 대부분의 투자자들은 어떻게 좋은 종목을 고를 수 있을지, 어떻게 고급정보를 얻을 수 있을지에만 열중하던 시기다. (지금도 그런 것 같다) 당시 컴퓨터와 가격데이터는 백엔드 시스템을 다루는 IT부서 정도에서나 중요하게 쓰이고 있었고, 대부분의 투자부서는 종목 분석 및 차트 기능 정도면 충분했다. 블룸버그 단말기는 1986년에야 5000 대를 돌파했고, 그리고, Windows 2.05 (3.1이 아니다)를 위한 최초의 Excel은 1987년에 출시되었다. 즉,
사람들은 포트폴리오 전략이 아닌 개별 종목을 분석하는데 정신이 팔려있었다.
전략C의 발견은 가능했지만, 누구나 쉽게 가능한 환경이 충분히 조성되지는 못했다.
심지어 1990년 Andrew Lo가 전략C에 관한 논문을 공개한 이후에도 투자자들은 별 관심을 갖지 않았고, 1995년에도 전략C의 일간 수익률은 1% 이상을 유지했다. 단일종목에 대한 관심에서 벗어나 전체 주식 유니버스에 전략C를 백테스팅하고 실행해볼 환경과 실행력을 갖춘 팀은 여전히 소수였으며, 먼저 움직인 팀들은 쉬쉬하며 엄청난 돈을 벌어들이게 되었다.
당시 먼저 움직였던 팀들은 D.E.Shaw, James Simons, Edward Thorp 와 같이 컴퓨터 공학자/수학자 출신으로 공학적인 접근으로 돈을 벌어보려고 했던 몇 안되는 월스트리트 아웃사이더들(이자 동시에 컴퓨터기술과 금융을 처음으로 같이 접할 수 있었던 아웃라이어들)이었고, 이 팀들이 전략C 등을 발견하게 되며 조용한 혁신이 시작되었다. 후일 전략C와 같은 형태의 투자전략은 통계적 차익거래(Statistical Arbitrage)라고 불리게 되며, 현재 대부분의 퀀트펀드들은 통계적 차익거래 전략을 사용한다.
혁신은 시작되기 어렵지만, 일단 시작되면 급격하게 강화된다.
퀀트펀드 전성시대: 퀀트펀드의 탄생과 새로운 균형
1세대 퀀트 헤지펀드들이 압도적인 수익률을 계속 보여주자 투자금이 몰려왔고 퀀트 헤지펀드들은 덩치를 더욱 불리게 되었다. 그 결과 2018년 기준으로 연봉 1.8조원을 받아 1위를 기록한 르네상스테크놀로지스의 제임스 사이먼스를 필두로 최고연봉 헤지펀드 매니저 중 절반 이상이 컴퓨터 알고리즘 트레이딩 방식을 사용하는 매니저들로 채워지기에 이른다.
통계적 차익거래를 최초로 시작한 팀 중 하나로 알려져있는 모건스탠리 자기자본트레이딩 그룹, 수학교수 제임스사이먼스의 르네상스테크놀로지스, 컴퓨터공학 교수 출신 Shaw(모건스탠리 자기자본트레이딩 그룹에 잠깐 있었다가 독립한다)의 D.E.Shaw&Co., 잉글랜더의 밀레니엄매니지먼트 등이 80년대 중후반 컴퓨터 알고리즘 트레이딩과 통계적 차익거래를 시작한 회사들이고, 1세대 회사에서 경험을 쌓은 인력 중 몇몇이 독립하여 2세대 퀀트펀드를 세워 좋은 성과를 올리게 된다.
밀레니엄매니지먼트 출신 게임프로그래머가 만든 월드퀀트, 모건스탠리 자기자본트레이딩 그룹에서 독립하여수학자 피터뮬러가 이끌고 있는 PDT 파트너스(금융위기 이후 볼커룰의 도입에 의해 대형금융기관의 자기자본트레이딩이 상당부분 금지되었고 그 결과 모건스탠리의 자기자본트레이딩 그룹은 PDT 파트너스로 독립한다.), D.E.Shaw&Co. 출신 국제수학올림피아드 은메달리스트가 만든 투시그마 등이 2세대 퀀트펀드에 속한다.
퀀트펀드들의 숫자가 많아지고 굴리는 돈도 커지면서, 반작용도 일어나기 시작했다. 제로섬의 속성을 가진 시장에서 왠만한 전략들은 대형퀀트펀드들이 동시에 재빠르게 찾아내고 이를 통해 엄청난 돈을 굴리게 되면서 수익률이 급감하게 된 것이다. 퀀트펀드들이 성장할수록 초과수익을 낼 수 있는 전략을 찾아내는 속도보다, 경쟁에 의해 수익이 감소하는 속도가 더 빨라지게 되었고 누가 더 많은 인원을 갈아넣어 더 많은 전략을 빠르게 찾아내느냐의 게임이 되었다. 그 결과 퀀트펀드들이 고용하는 인원은 점점 많아졌고, 상위 퀀트펀드들의 경우 1인당 운용자산이 300억원 수준까지 떨어졌다.
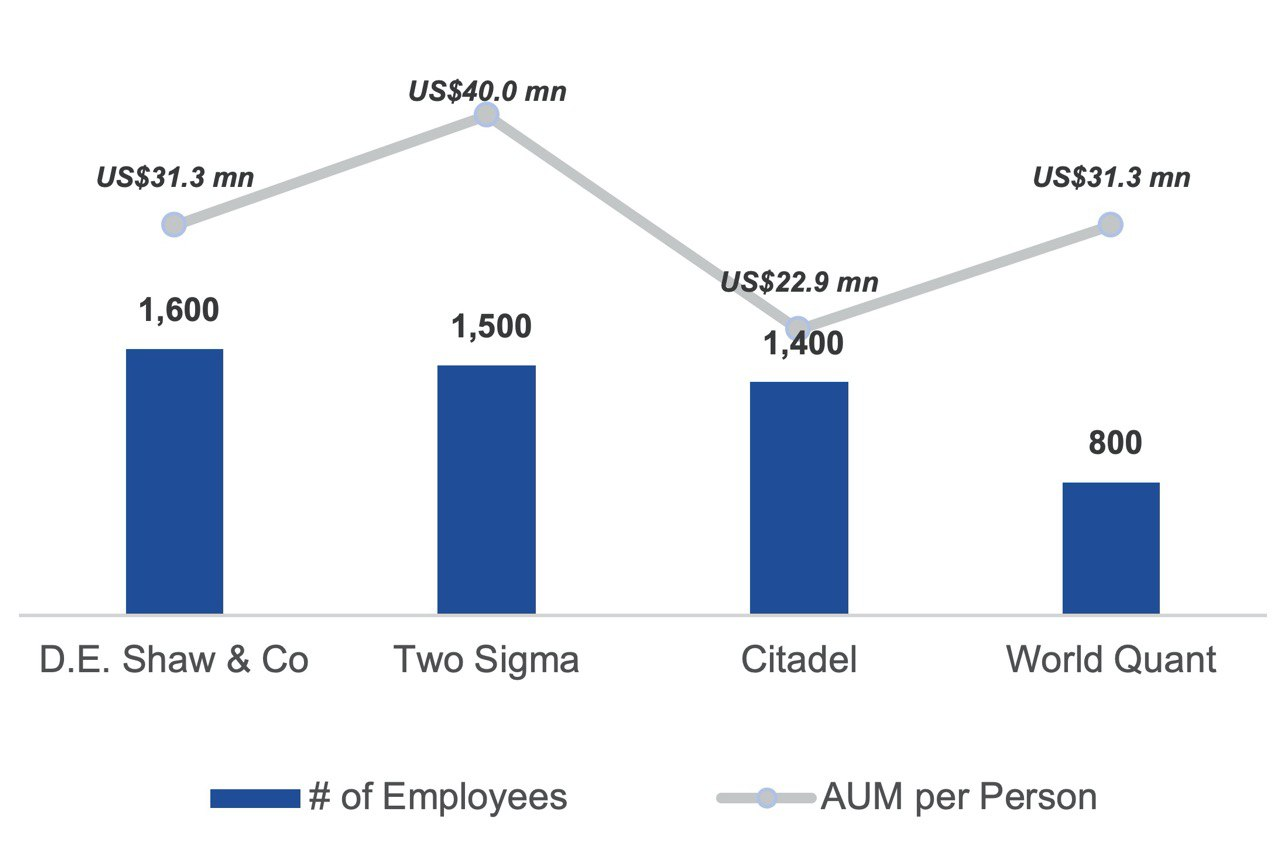 상위 퀀트펀드들의 직원 1인당 운용자산
상위 퀀트펀드들의 직원 1인당 운용자산퀀트펀드의 직원 1인당 보수와 간접비를 합치면 5억원이 넘는다. 1인당 300억원을 운용하게되면 최소 2%의 고정보수를 받아야 회사가 돌아갈 수 있는 것이다. 그래서, 거의 모든 퀀트헤지펀드들은 2-20 구조, 즉 연간 2%의 고정보수와 초과수익의 15~20%를 받는 구조로 운영된다. 저렴한 알파(초과수익전략)는 사라졌다.
ETF : 액티브에서 패시브로
헤지펀드가 단일종목이 아닌 포트폴리오에 통계적 차익거래를 적용하여 높은 수익률을 올리는 동안, 자산운용업계에서 투자상품이 고객에게 전달되는 방식에도 큰 혁신이 일어났다. ETF는 상장지수펀드로, 상장되어 거래되는 펀드이다. ETF는 전략C와 시기적으로 큰 차이가 나지않는 1993년 처음 등장했다. 초기에는 별 반응을 얻지 못했으나 시장의 알파(전략에 의한 초과수익)가 빠르게 사라지자 점점 많은 펀드들이 개별주식의 선별을 포기하고 인덱스를 통한 자산배분 등으로 방향을 잡으며 ETF를 활용하게 되자 ETF의 자산규모는 폭증했다. 2019년 말 기준으로 ETF의 총 자산규모는 5트릴리온달러, 약 6천조원에 이르며 성장세도 가파르다.
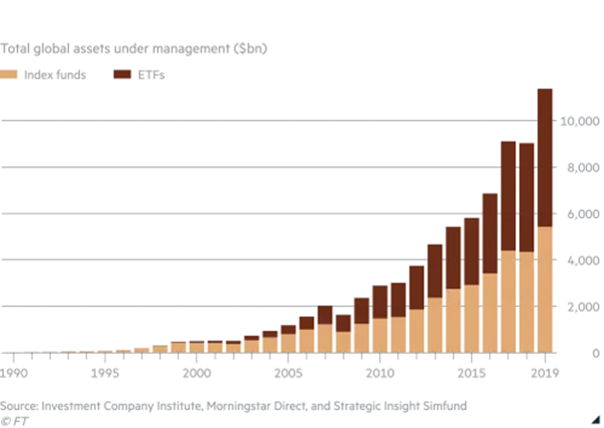
ETF는 편리함과 실시간 거래라는 중요한 특징을 가지고 있다. ETF 이전에는 S&P500 지수를 따라 투자하려면 일일히 지수구성종목을 비율대로 매수하거나, 이를 대신해주는 인덱스 펀드를 사야 했다. 시장에서 주식을 일일히 매수하면 실시간 거래는 만족시킬 수 있지만 매우 불편하고, 인덱스 펀드는 매매는 편하지만 매수/환매에 며칠의 시간이 걸리고, 하루에 한번 기준가가 나오므로 장중 변동에 대한 대응이 불가능해진다.
ETF의 인기는 계속 높아져서, 더 이상 초과수익을 내는데 실패하고 있는 높은 보수의 액티브 뮤추얼 펀드로부터 빠져나온 자금을 계속 흡수하고 있다. 2000년대 초반 이후로 액티브하게 운용되는 뮤추얼 펀드는 지속적으로 자금 유출을 겪고 있으며, 빠져나온 자금은 대부분 인덱스펀드와 ETF로 향하고 있다.

최근 무섭게 성장하고 있는 테크핀 기업, 금융 플랫폼 기업, 로보어드바이저 기업들도 ETF의 미래를 밝게한다. 테크핀 회사들은 실시간 고객데이터를 처리하여 개인화되고 맥락에 맞는 포트폴리오의 실시간 추천 및 판매, 관리를 추구하고 있다. 이런 모델에서, 포트폴리오는 ETF로 구성하는 것 말고는 딱히 대안이 없다.
펀드 등의 금융상품은 앞서 언급했듯이 하루에 한번 기준가가 나오고, 계약의 번거로움과 더불어 매수/환매에도 며칠의 시간이 걸리기 때문에 즉시성이 필요한 실시간 자산관리 서비스에는 사용될 수 없기 때문이다. 테크핀 회사가 "코스피지수가 갑자기 급락하고 있을때, 금을 검색한 고객에게 적절한 개인화된 포트폴리오를 플랫폼 내에서 즉시 제안하거나 오퍼레이션"하려고 한다면 ETF가 현재 유일한 방법이고 향후에도 그럴 것이다.
Active Index ETF
액티브인덱스, 스트래티직 베타, 액티브 베타, 스마트베타는 크게보면 다 같은 용어들이다. 지수를 단순히 추종하는 것에 그치지 않고, 전략적인 운용을 통해 지수대비 초과수익을 올리겠다는 운용전략을 의미한다. 현재 액티브 인덱스를 표방한 ETF의 규모는 약 100조원으로 전체 ETF 규모의 2%에 불과하나, 성장률은 ETF의 3배에 달할 정도로 급속도로 성장하고 있다. 투자의 목적은 높은 수익이므로 지수와 같게 움직이면서 지수대비 높은 수익을 낼 수 있는 ETF 가 있다면 지수 대신 선택하지 않을 이유는 별로 없다.
2019년 ETF.com의 글로벌 투자자 서베이에 따르면 응답자의 92%가 최소 한 개 이상의 액티브인덱스 ETF에 투자하고 있으며, 26%는 액티브펀드의 대안으로 액티브인덱스 ETF를 선택했다고 답했다. 또한 10조원 이상의 AUM을 가진 펀드 중 66%가 액티브인덱스 방식을 도입하고 있으며, 이 비율은 빠르게 늘어나고 있다.
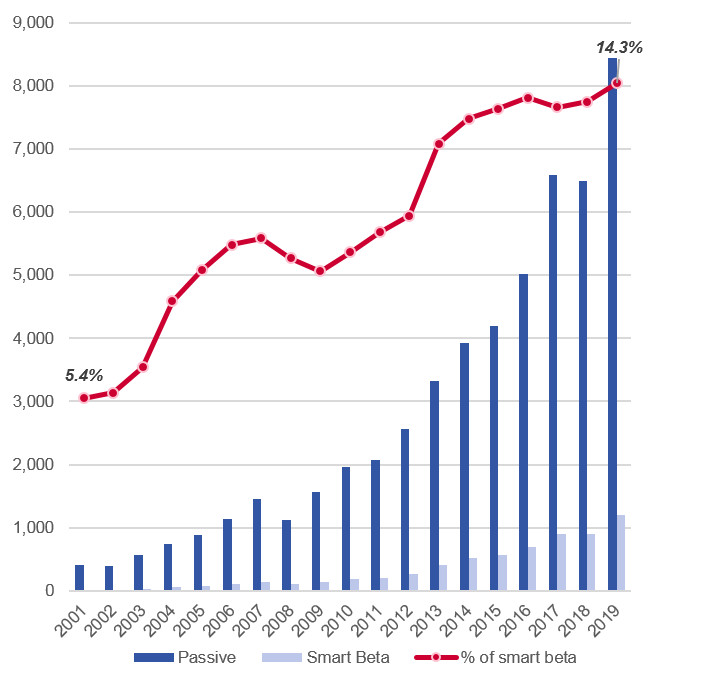
액티브인덱스 비지니스의 가장 큰 문제는, 앞서 퀀트헤지펀드의 사례에서 보았듯이 더이상 값싼 알파는 존재하지 않는다는 것이다. 그러나, ETF가 큰 시장을 가져오기 위해서는 연 1% 미만의 낮은 운용보수로 운용되어야 하며, 실시간으로 매매되는 특성상 성과보수도 받기 어렵다. 그리고, enhance 해야할 인덱스의 종류만 수천개에 달한다.
지금과 같이 노동집약적인 프로세스와 비용구조로는 답이 나오지 않는 것이다. 그래서, 현재 대부분의 액티브인덱스 ETF 들은 많아야 10개 정도의 팩터를 활용해, 팩터들의 선형결합 형태로 모델을 만들어 사용하는 식으로 운용되고 있고, 그 결과 그다지 좋은 성과를 내지 못하고 있다.
이 문제를 해결하기 위해서는 저비용과 알파(지수대비 초과수익)의 두마리 토끼를 동시에 잡을 혁신이 필요하다.
자동화된 퀀트리서치
퀀트 헤지펀드의 보수가 비싼 이유는 앞서 본 것처럼 알파를 찾는 과정에서 몸값이 높은 고급인력이 엄청나게 투입되어야 하기 때문이다. 퀀트펀드에 입사한 아이비리그를 졸업한 수재들은 데이터를 정리하고, 전처리하고, 가능성 있는 여러 아이디어를 백테스팅함으로써 초과수익전략을 찾아낸다. "공시가 나온 이후 모멘텀 전략이 잘 먹히는 듯 하다"라는 아이디어가 생겼다면, 수재들은 여러가지 버전의 백테스팅 및 포워드테스팅을 통해 알파를 찾아낼 것이다. 어떤 유니버스에 대해 더 잘 작동하는지 / 어떤 공시에 대해 더 잘 작동하는지 / 어떤 measure를 기반으로 한 모멘텀 전략이 더 잘 작동하는지 / 공시 후 얼마동안 더 잘 작동하는지 / ... 해볼 것은 너무 많고, 대부분은 무위로 돌아가며 엄청난 시간을 소모하게 된다.
IF
1) 특정 목표에 대한 포트폴리오 초과수익전략을 연구하는 속도를 높일 수 있다면,
2) 더 나아가 몸값 비싼 퀀트리서처들을 갈아넣지 않고도 자동으로 포트폴리오 운용전략을 추출할 수 있게 된다면,
THEN
알파를 액티브인덱스 ETF의 형태로 지금보다 많은 투자자들에게 저비용으로 제공하는 것이 가능해질 것이고, 엄청난 규모로 빠르게 성장하고 있는 액티브인덱스 시장에서 매우 유리한 고지를 점하게 될 것이다.
이 혁신이 가능한지를 따져보기 위해서는 문제를 보다 명확하게 정의하는 것이 필요할 것 같다.
자동 운용전략 추출의 문제와 AI
f(X,U) = P
X: 데이터집합 U: 투자유니버스 P: 성과
포트폴리오 운용전략을 찾는 것은 투자유니버스(U)와 인풋데이터(X)에 대하여 향후 성과가 좋을 것으로 예상되는 함수 f 를 찾는 것과 같다. 예를 들어, S&P500 지수의 투자유니버스는 [미국대형주]/ 인풋데이터X는 [시가총액] / 함수f는 [시가총액 비율대로 투자/ 분기마다 리밸런싱] 이다.
퀀트들이 하는 일은 위의 구조에서 간단히 정의하면 좋은 퍼포먼스를 가져올 것으로 예상되는 / 투자유니버스 U와 데이터 X를 인풋으로 하는 / 적절한 함수 f를 찾아내는 것이다.
예전에는 데이터 X의 후보로 모든 개별주식 가격데이터, 좀 더 나아가면 각 주식들의 재무데이터와 금리, 환율, 지수, 경제지표 등의 매크로데이터 정도만 고려하면 충분했다. (지금도 대부분의 퀀트는 이 세종류의 데이터만을 사용한다) 예를 들어, 전체 주식 중 PBR이 낮은 하위 10%의 주식을 매수하고 매년 리밸런싱한다는 함수는 인풋데이터로 주가와 순자산가치만 있으면 된다.
그러나 이러한 단순한 함수는 전략C와 마찬가지로 더이상 좋은 성과가 나지않는다. 이미 너무나도 많은 투자자들이 사용하고 있기 때문이다. 제로썸의 시장에서 남보다 먼저 발견하고, 남들도 같이 발견하기 쉽지 않은 투자전략 f를 찾아야 꾸준한 초과수익을 얻을 수 있다.
좀더 세분화하면,
[데이터 차별화] 남들이 잘 보지않는 데이터 X를 파라메터로 쓰는 경우
[투자유니버스 차별화] 투자유니버스가 동적으로 정의되는 등 복잡한 경우
[함수 차별화] f 자체가 복잡하거나 비선형 관계를 나타내고 있는 경우
에는 다른 리서처들이 상당기간 발견하기 어려울 것이다.
1. 데이터 차별화
데이터를 차별화하려는 시도는 듣기에는 팬시하지만, 의외로 성공사례가 거의 없다. 아무리 차별화된 데이터라도 실제 포트폴리오의 움직임과 무관한 데이터는 소용이 없고, 알파소스를 풍부하게 포함하면서 프라이빗한 데이터는 생각보다 잘 없기 때문이다. 다음의 사례들이 대표적이다.
대형 퀀트펀드 시타델은 자체 인공위성을 통해 빙하의 크기 등을 측정하고, 이를 통해 천연가스 선물 트레이딩(기온에 민감하다)에 활용하려는 계획을 세우고 실제 인공위성을 쏘아올렸으나, 성과미비로 결국 프로젝트를 폐기하고 위성을 모두 매각했다.
월마트 주차장의 주차대수를 위성으로 측정한 데이터를 트레이딩에 사용하려는 시도는 결국 실패했다.
뉴스를 자연어처리하여 종목별 센티멘트(투자자들의 기분)를 계산하고, 이를 통해 트레이딩을 했던 헤지펀드는 성과미비로 전략을 변경한다고 발표했다.
트위터 멘션 데이터를 트레이딩에 이용하려는 목적으로 만들어진 교수팀의 헤지펀드는 언론의 주목을 받으며 화려하게 오픈하였으나 성과미비로 조용히 문을 닫았다.
물론, 위의 사례들을 일반화할 수는 없다. 분명히 숨겨진 좋은 데이터를 사용하면 우위를 가지게 될 것이다. 그러나, 현재까지의 결과들을 보면 비공개 데이터를 통해 우위를 가져가려는 시도보다는 공개데이터에서 보다 좋은 전략을 찾아내려는 시도가 더 성공적이었음은 분명한 것 같다.
그 이유는 1) 비정형 데이터 중 상당수는 주가에 후행하고, 2) 데이터 샘플이 충분하지 못하거나 과거 데이터에 대한 충분한 백테스팅이 어려워서 오버피팅의 가능성이 높고, 무엇보다 3) 프라이빗 데이터에 존재하는 알파가 실제로는 별로 크지 않기 때문이 아닌가 추측된다.
어마어마한 양의 구글검색데이터를 접하면, 언뜻 느끼기에는 트레이딩에 도움이 될 엄청난 정보가 숨겨져있을 것 같지만, 실제 알파의 크기로 보면 가격데이터보다도 훨씬 적은 양의 정보만 존재하고 있는 것이 현실이다.
2. 함수 차별화 / 투자유니버스 차별화
주어진 데이터에 대해서, 남들이 미처 보지 못한 복잡한 패턴을 인지해서 이용할 수 있다면 초과수익을 얻을 가능성이 높아진다. 문제는, 사람의 뇌 구조가 비선형 패턴을 인지하는데 상당히 약한 모습을 보인다는 것이다.
저 PBR 주식에 투자하면 향후 주가가 오를 확률이 높다거나, 많이 오른 주식에 투자하거나 많이 내린 주식에 투자하면 향후 주가가 오를 확률이 높다는 식의 선형 패턴은 인간의 인식구조에 친화적이다. 그러나 예를 들어, 주가가 다음의 식을 상당한 확률로 따른다고 하더라도(아래의 식은 그냥 랜덤이다), 노이즈가 좀 끼어있다면 인간의 인식력으로 찾아내기는 쉽지 않을 것이다.
 아무렇게나 만들어본 비선형 관계식
아무렇게나 만들어본 비선형 관계식저렇게 복잡한 식이 아니더라도 기업의 사이즈에 따라 PBR 의 예측력이 달라지는 현상도 매우 간단한 비선형 패턴이고 잘 동작하는 알파의 원천이지만 찾아내기가 쉽지 않다. 연간 40% 이상의 수익률을 1985년~2005년까지 20년간 기록한 조엘 그린블라트의 단순한 마법공식도, 쉽게 발견되지 않았다는 것을 생각해보자. (마법공식도 전략C와 마찬가지로 1980년대 컴퓨터 기술의 도입과 더불어 백테스팅이 쉬워지면서 그린블라트에 의해 발견될 수 있었다)
즉, 함수 차별화를 위해서는 비선형 패턴을 쉽게 발견할 수 있는 도구가 필요하다. 전략C의 발견을 위해서 정리된 데이터와 컴퓨터가 필요했던 것처럼.
투자유니버스 차별화도 마찬가지이다. 크래프트테크놀로지스(필자가 몸담고 있는 회사이다)는 미국대형주의 개별종목이 공시이후 1~2개월간 모멘텀투자/가치투자 등의 팩터투자가 매우 잘 동작한다는 연구결과를 발표했다. 이 결과를 사람이 쉽게(더 나아가서는 자동으로) 찾아내기 위해서는, 미국대형주 개별종목에 대해 공시 이후 1~2개월간 특정 패턴이 어떻게 되는가를 쉽게 백테스팅할 수 있는 도구가 필요하다. 물론, 이 도구가 없이도 이론적으로 복잡한 코딩을 거쳐 해당 전략을 백테스팅할 수는 있다.
그러나, 찾을 수 있는 것과 찾는 것은 다르고, 이미 찾아낸 것을 듣고 백테스팅하는 것과 아무것도 없이 처음 찾아내는 것은 완전히 다르다. 사람들이 간단한 전략C를 (그 이전에도 충분히 할 수 있었지만) 데이터와 컴퓨터없이 쉽게 눈치채지 못했던 것처럼, 다이나믹한 투자유니버스(이 전략의 경우, 미국 대형주 중 공시가 나온지 얼마 안된 종목 유니버스)를 쉽게 다룰 수 있는 도구가 없다면 저런 투자전략은 찾을 수 없다.
즉, 투자유니버스를 더이상 고정된 상수로 다루지않고 다이나믹한 함수로 다룰 수 있는 도구가 있었기 때문에 다이나믹 투자유니버스에 대한 전략을 발견할 수 있었던 것이다.
그리고, 잘 설계된 딥러닝 모델은 이러한 비선형 관계 및 다이나믹 투자유니버스를 포함한 함수 f를 찾아내는 데 최고의 성능을 발휘한다.
3. 차원의 문제
백테스팅해볼 함수의 조합은 엄청나게 많다. 퀀트 리서처들이 사용할 수 있는 데이터 항목은 수천개가 넘으며, 투자유니버스의 자유도까지 생각하면 각 데이터 항목과 투자유니버스를 가지고 만들 수 있는 함수의 조합은 사실상 무한대이다. 바둑게임과 같은 상황이다. 모든 수를 다 테스트하여 함수(전략)을 발견하는 brute force 방식은 불가능하다.
경험많은 퀀트 리서처는 프로 바둑기사와 같이 모든 수를 굳이 둬보지 않더라도 어떤 데이터가 주가에 의미가 있을 것인지에 대한 리즈닝(인과관계 파악)과 유력한 함수의 형태를 직관적으로 파악함으로써 경우의 수를 좁히고 우수한 투자전략의 발견확률을 높인다. 경험많은 퀀트 리서처 없이 좋은 전략을 자동으로 추출하려면, 방대한 서치스페이스를 좁혀야 한다. 알파고는 딥러닝 기술을 포함한 몇가지 테크닉을 적용하여 이 문제를 해결하고, 인간의 능력을 초월하게 되었다.
딥러닝 기술은 알파고에서 보여준 것처럼 엄청난 차원의 스페이스에서 적절한 함수(투자전략)을 찾아내는 문제를 해결할 수 있다.
4. 오버피팅의 문제
오버피팅의 문제는 운용전략의 질을 담보하기 위해 반드시 해결해야하는 문제이다. 주어진 데이터를 전부 사용해서 모델을 피팅하는 것은 위험하다. 백테스팅 결과는 너무 좋게 나오겠지만 아웃오브샘플 테스트, 즉 실전에서는 절대 그런 성과가 나오지 않기 때문이다. 특히, 금융시장 데이터의 경우 시계열의 크기가 짧고 시장의 특성이 워낙 자주 바뀌므로 오버피팅의 문제에 대응하는 것이 쉽지 않다.
인간 리서처는 과거 데이터셋 전체에 잘 맞는 모델을 찾는 것도 많은 시간이 걸리기 때문에 과최적화를 감수하고 전체 데이터셋을 사용해서 모델을 만들고 리즈닝(전략의 합리성을 따져봄)을 통해 과최적화 확률을 줄이는 경우도 많다.
딥러닝을 적용하여 함수 f 를 자동으로 찾는 시스템을 구축한다면, 특정 시점의 예측(inference)에 그 시점 이전의 데이터만 사용하여 학습하도록 할 수 있다. 이는 과최적화 확률을 크게 감소시킨다.
5. 녹슨 전략의 문제
퀀트 리서치 방식으로 열심히 만들어놓은 전략은 기본적으로 정적인 투자전략이다. 즉, 매일매일 들어오는 새로운 데이터가 전략에 반영되지 않는다. 시간이 지나 전략이 시장과 괴리되어 잘 맞지 않게되면, 폐기하거나 새로운 데이터를 통해 전략을 유지보수해야만 하는 것이다. 그러나, 딥러닝 모델의 형태로 만들어진 투자전략은 매일매일 새로운 데이터를 피딩받아 학습하고, 신경망의 가중치가 약간씩 변하는 형태로 시장을 따라가게 되어 투자전략의 수명이 훨씬 길다. (물론 딥러닝 모델도 새로운 데이터 등이 입수되는 경우, 데이터 엔지니어와 AI 엔지니어가 모델 엔지니어링을 새로 해야하는 경우도 있다.)
AI enhanced ETF case
2019년 5월 미국 금융시장에 다소 생뚱맞은 사건이 일어났다. 한국의 AI 스타트업 크래프트테크놀로지스가 2019년 5월 21일 뉴욕증권거래소에 AI로 운용되는 액티브인덱스 ETF 두 개를 상장한 것이다.

상장된 ETF인 NYSE: QRFT는 S&P500 지수를 enhance 하는 것을, NYSE: AMOM은 S&P500 모멘텀지수를 enhance 하는 것을 목표로 하고 있는 액티브인덱스 ETF 이다. 딱 1년이 지난 지금 위 AI ETF 들은 다음과 같은 성과를 보여주고 있다.

 QRFT 의 성과
QRFT 의 성과NYSE: QRFT의 경우 상장 이후 1년동안 벤치마크인 S&P500 지수를 (토탈리턴/보수차감 후 기준) 11.60%p 아웃퍼폼하고 2배가 넘는 샤프비율을 기록하는 놀라운 성과를 기록했다. NYSE:AMOM 의 경우도 S&P500 지수를 11.50%p 아웃퍼폼하고 약 2배의 샤프비율을 기록했다.
피어 ETF인 블랙락, 골드만삭스 등의 액티브 인덱스 ETF 들과 비교해보아도 압도적인 성과이다. QRFT는 같은 카테고리에서 2위인 골드만삭스의 GSLC보다 1년동안 10%p 이상 좋은 성과와 2배 이상의 샤프비율을 기록했고, AMOM 역시 2위인 블랙락의 MTUM을 6.6%p 앞섰고 샤프비율도 1.4배 이상을 기록했다.
(2020-10-14 기준 QRFT, AMOM 은 각각 44.79%, 55.76%의 누적수익률을 기록하여 벤치마크를 각각 18%p, 31%p 앞서고 있다.)
미국대형주 고배당 컨셉의 액티브 인덱스 ETF로 2020년 2월 27일에 상장된 Qraft AI Enhanced U.S. Large Cap High Dividend ETF (코드명 NYSE: HDIV, 국내증권사 해외주식 HTS에서는 코드명 HDIV 검색하면 된다) 의 경우도 아직 기간은 짧지만 미국 대형주 고배당 ETF 그룹에서 가장 좋은 성과를 보이고 있다.
이러한 성과보다 훨씬 더 중요한 사실은 위의 AI ETF들이 AI 시스템에 의해 자동으로 추출된 운용전략으로 만들어졌다는 것이다.
자동화된 데이터 전처리 시스템 + 딥러닝 기반 자동 운용전략 추출 시스템을 통해 위의 AI ETF 들은 한 달도 안되는 시간에 제작과 테스트가 완료될 수 있었다. 크래프트테크놀로지스는 이러한 AI 시스템을 통해 5명의 인원이 1달동안 최소 5개의 액티브인덱스 ETF를 제작할 수 있는 생산성을 확보하고 있다. 대형운용사의 경우 하나의 액티브인덱스 ETF를 출시하기 위해 주니어퀀트 포함 5~10명의 인원이 투입되어 6개월~1년의 시간이 걸린다.
AI 에 의한 운용전략 자동추출
기존 퀀트 운용방식은 크게 데이터처리->전략리서치->주문집행의 단계로 이루어진다.
데이터처리 단계에서는 복잡한 금융 데이터를 시뮬레이션을 위해 바이어스가 없도록 잘 처리하고 / 전략리서치 단계에서는 처리된 데이터를 이용해 alpha source를 리서치하고 포트폴리오 전략화시키는데 굉장히 많은 리서치 인력이 투입되며 / 만들어진 퀀트 전략들에 대한 대규모 매매를 진행하는 과정에서 시장충격 최소화를 위한 복잡한 주문집행(트레이딩)도 필수적이다.
크래프트테크놀로지스는 액티브인덱스 ETF를 양산하기 위해 각 단계들을 모두 AI 시스템화 하였다.
 출처: 크래프트테크놀로지스
출처: 크래프트테크놀로지스이를 위한 전체 시스템 구조는 다음과 같다.
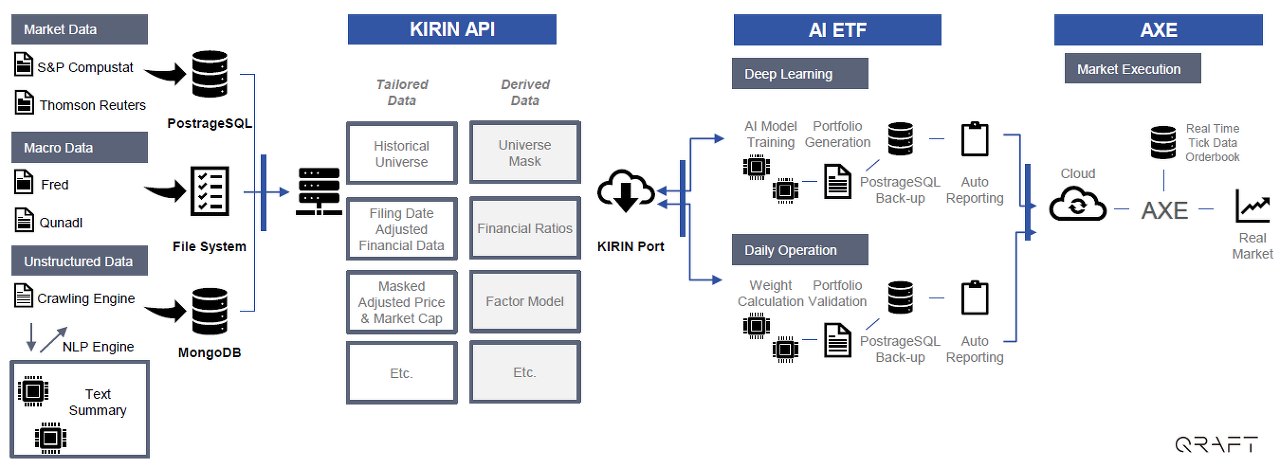 출처: 크래프트테크놀로지스
출처: 크래프트테크놀로지스중요한 것은, 얼마나 심플한 구조로 복잡한 모델을 테스트할 수 있는 환경을 만들 수 있느냐다. 그래야 이를 자동화할 수 있다.
1. 데이터 처리 시스템 (KIRIN API)
S&P 글로벌, Refinitiv(구 톰슨로이터)와 같은 데이터벤더의 금융데이터는 바로 쓰기가 매우 어렵다. 생존편향 바이어스(상장폐지 종목의 정확한 처리) 및 미래참조 바이어스(3분기 기업실적이 실제로는 4분기에 발표가 되었는데, 3분기에 들어가 있다든가 하는) 등을 제거하는 작업과, 주식의 M&A, 유상증자, 상장 및 상장폐지, 재상장 등의 이벤트를 정확하게 전처리하는데 엄청난 시간이 들어간다. 크래프트테크놀로지스의 데이터처리 시스템은 GPU로 가속된 병렬연산작업을 통해 이러한 전처리 작업을 자동화해준다. (https://youtu.be/bsxUPNTSDjA)
데이터처리 시스템은 단순히 데이터를 모아서 저장하는 역할에 그치지 않고, 이를 전처리하고 정리하여 여러가지 뷰로 투자유니버스를 테스트할 수 있도록 되어있다. 예를 들어, "특허관련 최종 공시가 나온지 2개월이 경과하지 않은 기업"과 같이 투자유니버스를 정의하고 이에 대한 투자전략을 간단한 python 코드 몇 줄로 테스트해볼 수 있다. (즉, 이런 투자전략을 쉽게 발견할 수 있고 자동으로 발견할 수 있게 한다) 이 시스템은 API화되어 있으며 곧 독립된 솔루션으로 대형 클라우드 플랫폼을 통한 상용화를 앞두고 있다.
2. 전략추출 시스템 (ALPHA FACTORY)
AI 리서치 시스템의 핵심은, 투자전략의 자동추출이다. [투자유니버스(U) 자유도] * [데이터(X) 자유도] * [함수 형태 (f) 자유도]가 곱해진 엄청난 크기의 서치 유니버스는 바둑의 서치 유니버스보다 훨씬 방대하다. 이 방대한 서치유니버스 안에서 확률높은 후보를 좁히고, 후보들을 자동으로 백테스트/포워드테스트하여 최종적으로 투자전략을 추출하는데 있어 적절히 엔지니어링된 딥러닝 모델은 상당한 성과를 보인다. 딥러닝을 통한 투자전략의 자동추출은 2단계로 나누어져 있다.
1) 팩터팩토리
팩터팩토리는 초과수익의 가능성이 있는 기본 패턴을 AutoML 기술 등을 통하여 자동으로 탐색하는 시스템이다. nVIDIA DGX 서버 1대 기준으로 인간의 개입없이 하루에 10개 이상의 패턴(팩터)을 찾아낼 수 있다. 전기는 많이 소모하지만, 높은 급여는 안줘도 되고 이직도 없다.
 팩터팩토리에서 추출된 팩터와 팩터 성과 예시 (출처: 크래프트테크놀로지스)
팩터팩토리에서 추출된 팩터와 팩터 성과 예시 (출처: 크래프트테크놀로지스)*크래프트 팩터팩토리는 전 세계의 금융학자들이 열심히 데이터를 분석하여 탐색해온 asset pricing model 을 재발견하기도 했다.
https://brunch.co.kr/@qraft/21 (AI 가 노벨경제학상을 탈 수 있을까?)
*팩토리에 대한 좀더 자세한 내용은 다음 크래프트 뉴스레터를 참조
https://www.qraftec.com/research/2020/6/14/qraftnbspai-quant-series-001-factor-factory
2) 전략팩토리
팩터팩토리를 통해 찾아낸 팩터들은 독립된 소스가 아니기 때문에 선형결합보다는 비선형 결합모델로 구성하는 것이 더 적합하다. 전략팩토리에서는 팩터팩토리에서 자동으로 추출된 팩터들을 비선형적으로 조합하여 비선형 자산가격모델을 만드는 형태로 최종 투자전략을 찾아낸다. 팩터팩토리를 통해 더 많은 팩터들이 누적될수록 전략팩토리에서 점점 더 정교한 자산가격모델을 만드는 것이 가능해진다.
3) 넥스트 밸류 ETF의 사례
가치팩터, 즉 가치투자의 성과가 예전에 비해 눈에 띄게 떨어지고 있는 현상에 대해서 많은 연구가 이루어지고 있다. 많은 논문이 발표되었지만, 가치투자의 시대가 끝난 것이 아니라, 전통적인 산업구조에 맞춰서 설계된 밸류에 대한 측도가 잘못되었을수도 있다는 연구가 힘을 받고 있다.
전통적인 방식의 가치투자는 장부가치와 시가총액을 비교하여 투자한다. 그러나 장부가치는 자산-부채 회계 시스템 하에서 자산에는 주로 유형자산만 계상되고, 무형자산은 측정의 불확실성으로 인해 비용으로 처리되어 제대로 반영되지 못하고 있는 것이 가치팩터가 힘을 잃은 원인이라는 것이다. 해당 연구는 정보화와 기술의 발전에 따라 유형자산보다는 무형자산의 중요성이 기업의 실제 가치에 훨씬 더 중요한 요인이 된 것이 장부가치 중심의 가치 측도가 맞지 않게 된 주원인이라고 분석한다. (아마존에게 보유한 물류창고(유형)와 배송시스템(무형) 중 어떤 것이 더 중요할지를 상상해보면 쉽다.)
크래프트테크놀로지스는 인풋데이터로 R&D 비용, 마케팅 비용, 조직관련 selling, general, administrative expense, 특허 issuance 등을 사용하여 정확한 무형자산 측도(즉 함수 f)를 알파팩토리를 통해 자동으로 추출하였고, 이를 통해 가치투자의 성과를 크게 개선시킬 수 있었다.
이렇게 제작된 Qraft AI Enhanced Next Value ETF (티커: NVQ)는 2020년 11월에 뉴욕증권거래소에 상장된다. (블룸버그 관련기사)
3. 주문집행 시스템 (AXE)


컴퓨터 알고리즘에 의한 주문집행(execution) 시스템의 역사는 매우 길다. 그러나 대부분의 자동화된 주문집행 시스템은 VWAP, TWAP, IS 등의 사전에 정의된 룰베이스의 알고리즘을 사용하고 있다. JP모건체이스는 세계최초로 주식 개별 종목의 틱데이터에 딥러닝 강화학습 기술을 적용한 AI 주문집행시스템 LOXM 을 발표하여 언론의 큰 주목을 받았고, 곧이어 골드만삭스도 AI 주문집행시스템을 개발하여 테스트 중인 사실을 공개했다.
크래프트테크놀로지스 역시 주식 틱데이터에 딥러닝 강화학습 기술을 적용한 AI 주문집행시스템을 개발하였고, 이를 세계최초로 신한금융투자에 제공하여 상용화하였다. (JP모건과 골드만삭스는 이를 내부용으로만 사용하고, 외부에 제공하지 않는다.) 크래프트테크놀로지스는 상대적으로 늦게 개발에 착수하여 그사이 발전한 최신 AI 강화학습 모델을 적용할 수 있었다. 알파고에 쓰였던 DQN 모델을 사용하여 만들어진 JP모건의 LOXM과는 달리, 크래프트테크놀로지스는 보다 최신의 에이전트 기반 강화학습 모델을 응용하여 주문집행의 성과를 크게 끌어올렸다. (https://youtu.be/o3m6Ewjc7Lw)
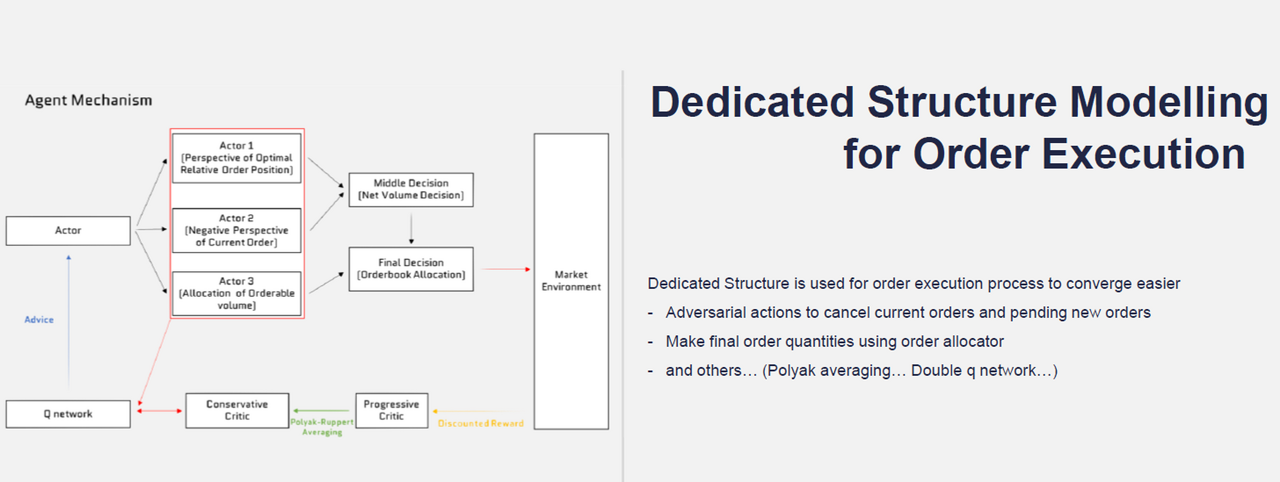 크래프트테크놀로지스 AXE에 적용된 인공지능 모델
크래프트테크놀로지스 AXE에 적용된 인공지능 모델2018년 말에 증권사 딜러와 AXE에게 같은 (KOSCOM에서 랜덤하게 생성한)대형주 포트폴리오를 주고 누가 더 싸게 포트폴리오를 시장에서 살 수 있는지를 5일간 대결했던 AXE Challenge (총상금 1억원 / nVIDIA, 신한은행, KOSCOM, PwC 후원)가 열렸다. TV에 생중계된 이 대회에서 AXE 시스템은 증권사의 인간 딜러를 큰 차이로 제압했다.
AXE는 2020년 3월부터 신한금융투자의 법인 주문집행에 적용되었다. 현재까지 국민연금이 위탁한 약 3천억원의 주식주문을 AI 로 처리하였으며, VWAP 대비 뛰어난 성과를 보여주고 있다. (2020년 5월 기준)
이러한 AI 주문집행 시스템은 개별종목의 가격, 거래량 뿐만 아니라 체결내역, 지정가 호가 등을 포함한 틱데이터에서 패턴을 학습하여 최적 주문집행 전략을 탐색한다. 이러한 시스템이 도입될 경우, 액티브인덱스 뿐 아니라 모든 금융상품의 대량거래에 따른 거래비용을 최소화하여 수익률을 개선할 수 있다. 특히 마켓임팩트가 큰 초대형 펀드 또는 중소형주를 대상으로 하는 펀드에서 그 효과가 크다.
크래프트테크놀로지스는 최근 AI 주문집행시스템 AXE를 마이크로소프트와 함께 클라우드 솔루션 형태로 패키징하고 있음을 밝혔다. 클라우드 솔루션화가 완성되면 모든 금융기관이 API 연결을 통해서 자사 서비스에 AXE를 적용할 수 있게 된다.
예를 들어, 메신저 플랫폼 기업이 호가창 기반의 복잡한 주문 UI를 가진 MTS를 없애고, "앞으로 일주일 동안 Apple 5천만원 어치 좋은 가격에 사줘" 같은 자연어 또는 음성 명령 기반의 브로커리지 서비스를 도입할 수 있게 되는 것이다. 이러한 UI/UX 가 확산되면 지금과 같이 호가창을 보면서 주문가격, 시장가/지정가 선택 등이 필요한 복잡한 MTS는 금새 설 자리를 잃어버리게 될 것이다.
세계 최대의 GPU 기업인 엔비디아는 최근 전세계 AI 스타트업 중 30개를 선정하여 특별 지원하는 inception premier 프로그램에 크래프트테크놀로지스를 선정했다. 국내 기업으로는 최초이고, 전세계에서도 금융분야 AI 기업으로는 최초이다. (다른 선정기업들은 대부분 유니콘이거나 이미 Apple 등에 인수된 유명 AI 스타트업이다.) 선정기업들의 면면을 보면, GPU가 많이 소요되는 자율주행, 비전 쪽의 AI 기업이 대다수다. 엔비디아가 금융분야의 첫 프리미어 회원사로 크래프트테크놀로지스를 선정한 것은 AXE가 글로벌 금융시장에 침투하게 되면 nVIDIA 의 GPU 역시 금융기관에 많이 팔릴 것임을 예상한 포석일 것이다. (주문집행의 경우, 주문하는 고객이 많아질수록 더 많은 실시간 동시처리 능력을 요구하며, AXE는 학습과정 및 추론과정에서 많은 병렬 GPU 컴퓨팅 파워를 필요로 한다.)

지금은 또다른 1990년의 시작인가?
1990년에 앞선 몇 명은 데이터와 컴퓨터를 통해 전략C를 발견할 수 있었고 큰 혁신을 이루었다.
2020년에 앞선 몇 명은 AI 기술의 발전을 자산운용업에 적용하여 자동화된 알파라는 큰 혁신을 이룰 수도 있다.
 AI 기반 운용사 모델
AI 기반 운용사 모델AI 기반의 운용사 모델은 새로운 데이터를 찾고 엔지니어링할 데이터 엔지니어팀과, 보다 좋은 전략추출 효율을 가능하게 하는 딥러닝 모델을 엔지니어링할 AI 엔지니어 팀만 필요하다. 그리고 데이터 소스 및 주문집행용 틱데이터 소스를 구독하는 비용만 들어간다. 개발하고 운용할 ETF가 아무리 많아져도, 서버 증설 이외의 다른 비용은 없다. 먼 미래의 모델이 아니라 지금 당장 실현되고 있는 모델이다.
무르익은 딥러닝 AI 기술을 적용하여, 인간 리서처들이 도저히 달성할 수 없었던 투자전략 발견 효율(알파팩토리)과 새로운 전략형태의 발견(다이나믹 투자유니버스 전략 등/알파고의 인간의 바둑상식으론 해석하기 어려웠던 신선한 수)을 가능하게 만든 팀이 있다면 그 아웃라이어 팀은 지금 출현할 것이고 / 좋은 액티브 인덱스 성과를 만들 것이고 / 액티브인덱스 ETF 시장에서 중요한 위치를 점할 것이다. 어쩌면 1경원을 향해 가고있는 ETF 시장에 AI 기술을 통해 저렴한 알파를 공급하게 되는 혁신의 시작점이 지금일지도 모른다.
크래프트 브로셔 받기:
다음글: AI 플래그십 헤지펀드 만들기
크래프트테크놀로지스는
AI 기술을 활용해 자산운용업의 비효율성을 혁신하고 있는 기업입니다. 데이터처리부터 알파리서치, 그리고 포트폴리오 주문집행까지 자산운용업의 각 단계별 비효율성을 기술로써 해결하고, 이를 통해 높은 수준의 알파를 낮은 비용으로 제공하는 것을 목표로 합니다. 복잡한 금융 데이터 전처리를 자동화하고, 병렬컴퓨팅을 통해 고속화하며, 이를 통해 완성된 시뮬레이션 환경에서 AutoML 기술을 통해 알파 팩터를 자동으로 서칭합니다. 이렇게 찾아진 알파 팩터들을 활용해 정해진 펀드 컨셉에 따른 펀드 유니버스에 따라 Strategy Factory을 통해 딥러닝 기반의 Deep Asset Pricing Model을 만들고, 모델을 통해 생선된 최종 포트폴리오는 강화학습 기반의 주문집행 엔진 AXE로 효율적인 주문집행을 하는 것을 목표로 합니다. 위 시스템을 통해 제작되고 뉴욕증권거래소에 상장된 크래프트테크놀로지스의 AI ETF 라인업은 인공지능 시스템으로 100% 무인운용되고 있으며, 상장 후 1년동안 벤치마크지수(S&P500, S&P500모멘텀 지수)를 10%p 이상 아웃퍼폼하는 등 동종 ETF 중에서 최고의 성과를 보여주고 있습니다.
크래프트 웹페이지: http://www.qraftec.com
크래프트 뉴스레터 구독: https://www.qraftec.com/newsletter
Disclaimer
*과거의 성과가 미래의 성과를 보장하지 않습니다.
*본 자료는 정보제공을 위해 작성되었으며, 펀드 등 금융투자상품의 판매를 권유하기 위한 목적으로 사용될 수 없습니다.
*본 자료는 크래프트테크놀로지스가 특허출원 중이거나 특허등록한 내용을 포함하고 있습니다.